2013-ban a Skype-nál dolgoztam, ahol a csapatom a Skype-ot az Outlook.com webes levelező jobb oldali sávába integrálta. A projekt sikeres volt, és ekkoriban 400 millió ember használta a levelezőt, és vele a Skype-ba való automatikus bejelentkezést. 2014-ben úgy döntöttük, hogy gyökeresen megváltoztatjuk az alkalmazás architektúráját: az addigi kliens oldali logikát szerver oldalira cseréljük. A cél az volt, hogy jóval gyorsabban töltődjön be a Skype. Egy szemléletes hasonlattal élve: repülés közben a légcsavaros motorokat sugárhajtásúvá cseréljük le, úgy, hogy az utasok közben semmit se vegyenek észre.
Persze, ha 400 millió "utasról" beszélünk, akkor még egy rutinmunka is kevésbé triviális - nem hogy egy bonyolultabb változtatás. Viszont nem egy kezdő csapatról beszéltünk: egy összeszokott, közepesen szenior csapatunk volt, akik tudták, hogy mit csináltak. Ez nekünk csak rutinmunka volt, ahol nem igazán számított, hogy 1,000 embernek, vagy 400 milliónak csináljuk meg. Legalábbis ezt hittük eleinte. Aztán útközben megváltozott minden.
"10% rollout, minden zöld és stabil. CPU utilization a 80 VM-en, 4 data centerben átlagosan 5% alatti, traffic 900 req/sec, közel nulla hibával az elmúlt 120 percben."
"Oké, toljuk 20%-ra."
"Extra 40 millió embernek? Biztos vagy benne?"
"Már 36 órája semmi vészes nem történt, duplázzuk meg a rolloutot, mert egyébként örökké fog tartani, és a héten végezni akarok. Mehet!"
"Rendben, 20% élesítve. A keleti part most ébred, a terhelés java a keleti parti és európai data centerekre fog befutni, ázsia minimális lesz. Dőljünk hátra és nézzük a rolloutot."
"Basszus, mi történik? Európa 5%-os hibával, fut, és egyre csak nő! 7%... 10%...
"Látom én is. Mit csináljunk? Keleti part, nyugati part és Ázsia egészséges, pedig ott is nő a terhelés."
"Vedd ki Európát a rotációból azonnal!"
"Kivettem... a load nagy része átmegy a keleti partra... de mi a fene történik?? 15% reject - nem, már 17%, folyamatosan nő! Teljesen abnormális. Meghal a rendszer! Mi a francot csináljunk?? Vegyük ki a keleti partot is?"
"Rollback, rollback, rollback! Most! Az istenre vársz már?"
Na, szóval még sem volt ez olyan sima ügy, mint ahogy terveztük. Na de talán kezdjük az elejéről.
Túl sokáig tölt be a Skype a weben
Szóval az egész onnan indult, hogy a csapatom integrálta a Skype-ot az Outlook.com-ba. Ez akkoriban volt, amikor a Microsoft megölte a Hotmail.com-ot, és mindenkit átirányítottak az Outlook-ra. Őszintén szólva pofásan megcsinálták az Outlook.com-ot, mi pedig pofásan integráltuk a Skype-ot, a jobb oldali sávba. Így nézett ki akkoriban:
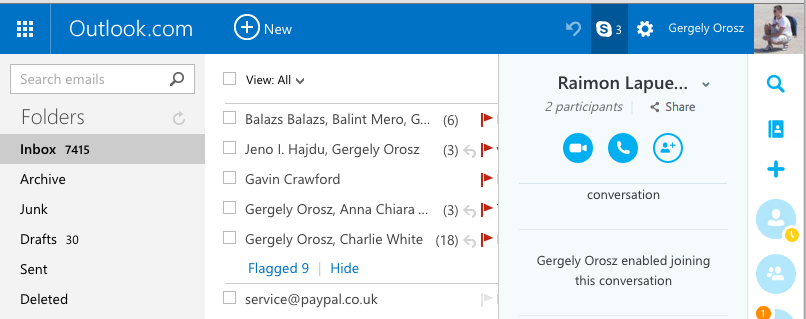
Miután beraktuk a Skype-ot, elkezdtük nézni, hogy mennyire is működik jól. A legnagyobb gondnak az tűnt, hogy sokszor csomó idő volt, amíg a levelezőbe bejelentkezés után elindult a Skype: sokszor 5-15 másodpercet is jelentett. Emellett másodlagos gondként az is előjött, hogy nem volt elég logunk arról, hogy pontosan mennyi ideig is tart a bejelentkezés, mert rengeteg minden kliens oldali hívásokkal történt.
Konkrétan a JavaScript kód egymás után 3 különböző requestet indított, hogy bejelentkeztesse a felhasználót. Ha ezek közül bármelyiknél hiba lépett fel, akkor újra kezdte a folyamatot - közben viszont alig loggolt valamit. Mivel 400 millió emberről beszéltünk, logok viszont nagyon kellettek nekünk: pontosan akartuk tudni, hogy naponta 10, 100 vagy 1 millió ember nem tudott-e bejelentkezni a Skype-ra, az Outlook.com-on.
Úgyhogy elhatároztuk, hogy három legyet ütünk egy csapásra: meggyorsítjuk a webes bejelentkezést, több logot gyűjtünk, és egyben leegyszerűsítjük az alkalmazás kódját. És hogy mindezt hogyan? Úgy, hogy a bejelentkezés hívásait a kliens oldalról átvisszük a szerver oldalra. Vagyis egy egyszerű proxyt építünk:
- Korábban, a kliens oldalon 3, egymást követő requestet csinált az alkalmazás. Itt egy csomó logika volt lekezelni, hogy mi történik, ha az első, vagy a második, vagy a harmadik request nem sikerül; hogyan próbálkozik újra az app
- Mindezt átvisszük a szerverre. Így a kliens csak egyetlen requestet csinál a szerver felé, a szerver pedig ezt a 3 requestet megteszi sorban.
- Ezzel meggyorsul a rendszer: a szerverünk sávszélessége ugyanis nagyobb, és később még azonos data centerbe is tudjuk mozgatni, a többi Skype-os rendszerrel, még kisebb késleltetéshez
- Ráadásul most már több üzleti logika van a szerveren, ami megkönnyíti a logolást, illetve az azonnali változtatást (és akár hot patchelést is)
A Skype webes kliensünk egy saját Javascript fájlban töltődött be, amit a mi csapatunk hosztolt, a https://swx.cdn.skype.com/shared/v/{VERZIÓ}/SkypeBootstrap.min.js címen. A kliensen a Javascriptet Knockouttal használtunk, a CSS-t SASS-al generáltuk. A szerver oldalon a csapatunk C# kódot futtatott ASP.NET MVC keretrendszeren. A kliens build rendszerünk Grunt volt, a szerveré MSBuild és TFS. A Javascript unit- és integration tesztek Sinon keretrendszert használtak, a C# unit / integration tesztek pedig Moq-ot.
A fejlesztés folyamán a minőséget nagyon komolyan vettük. Minden kód változtatást 2 másik csapattag kellett, hogy reviewi-olja, és jóváhagyja. Ehhez egy belső szoftvert használtunk, ami a Fisheye-hoz volt hasonló. Új release előtt manuálisan végigteszteltük az appot, majd fokozatosan rollout-oltuk az összes felhasználónak. Közben meg figyeltük az analitikát, hogy minden fontos szám - mint sikeres bejelentkezés, vagy hívások száma - rendben van-e.
Voltak automatikus tesztjeink, de nehezen tudtuk automatizálni az end to end hívások, illetve videó hívások tesztelését különböző böngészőkön - így sajnos még mindig több manuális tesztünk volt a végén, mint szerettük volna. Mostanra, 2 évvel később, ahogy hallottam, a csapat már a legtöbb, hívásokkal kapcsolatos tesztet automatizált, így manuális tesztelés nélkül is tudják frissíteni a rendszert.
Hogyan építsünk 400 millió embert kiszolgáló proxyt?
Azzal, hogy egy új szerver oldali réteget készültünk berakni, tudtuk, hogy rengeteg requestet kell tovább proxzynunk. A becsléseink alapján csúcsidőben akár 15,000 req/sec-et kell gond nélkül lekezelnünk. 2014-ben nem volt kérdés, hogy cloudot használunk erre. Ráadásul, mivel a Skype a Microsoft része volt, a technológia, az Azure is adott volt - mivel az Azure a Microsoft cloud szolgáltatása. Bónuszként belsős csapatként pedig nagyon nyomott áron is tudtuk igénybe venni, vagyis (eleinte) a költség nem volt a legfontosabb tényezőnk.
A proxy, amit építeni akartunk, egy rém buta proxy volt, minimális logikával, és semmi adattárolással (a logokon kívül). ASP.NET MVC-vel, C#-ban írtuk meg, majd a lehető legegyszerűbb cloud megoldást választottuk: Windows-os virtual machine-eket indítottunk az Azure-ban, ezeket pedig felskáláztuk. Vagyis kiválasztottuk, hogy hány virtual machine fusson a felhőben, ami kiszolgálja a hívásokat. Ha túl nagy lenne a terhelés, csak új gépeket indítunk - ami csak egy kattintás az Azure menedzsment felületén. Mivel a szerverünk nagyon egyszerű volt, a skálázás is pofon egyszerűnek ígérkezett.
Persze, egy ekkora méretű rendszernél fontos volt, hogy (lehetőleg) mindig működjön. A virtual machine-ekkel pedig az a baj, hogy bármikor meghalhatnak. Sőt, egy egész data center is akadozhat - ahogy azt az Azure status oldalán lehet követni. Azért, hogy ilyen hibák alkalmával se álljon le az alkalmazásunk, több data centerben indítottunk virtual machine-eket. Konkrétan 4 data centert használtunk: USA nyugati part, USA keleti part, észak-Európa és Japán. Az Azure Traffic Manager komponenst belőttük a négy data center elé, és ez automatikus load balancinggel mindig a legközelebbi egészséges data centerhez irányította a forgalmat.
... és nagyjából ennyi is volt a proxy megírása. Az egész folyamat egy hónapig se tartott: lokálisan már működött is az "új" rendszer.
Ideje befrissíteni mind a 400 millió ember alatt a weboldalt
Szóval megvolt az új, csili-vili, javított rendszer, és leteszteltük, hogy működik a tesztkörnyezetünkben, ahol körülbelül 2,000 belsős, Microsoftos ember használta. Következő lépés? Minden Outlook.com felhasználónak kirakjuk? Dehogyis. Ami 2,000 embernek működik gond nélkül, az 400M embernek... nem biztos, hogy gond nélkül fog.
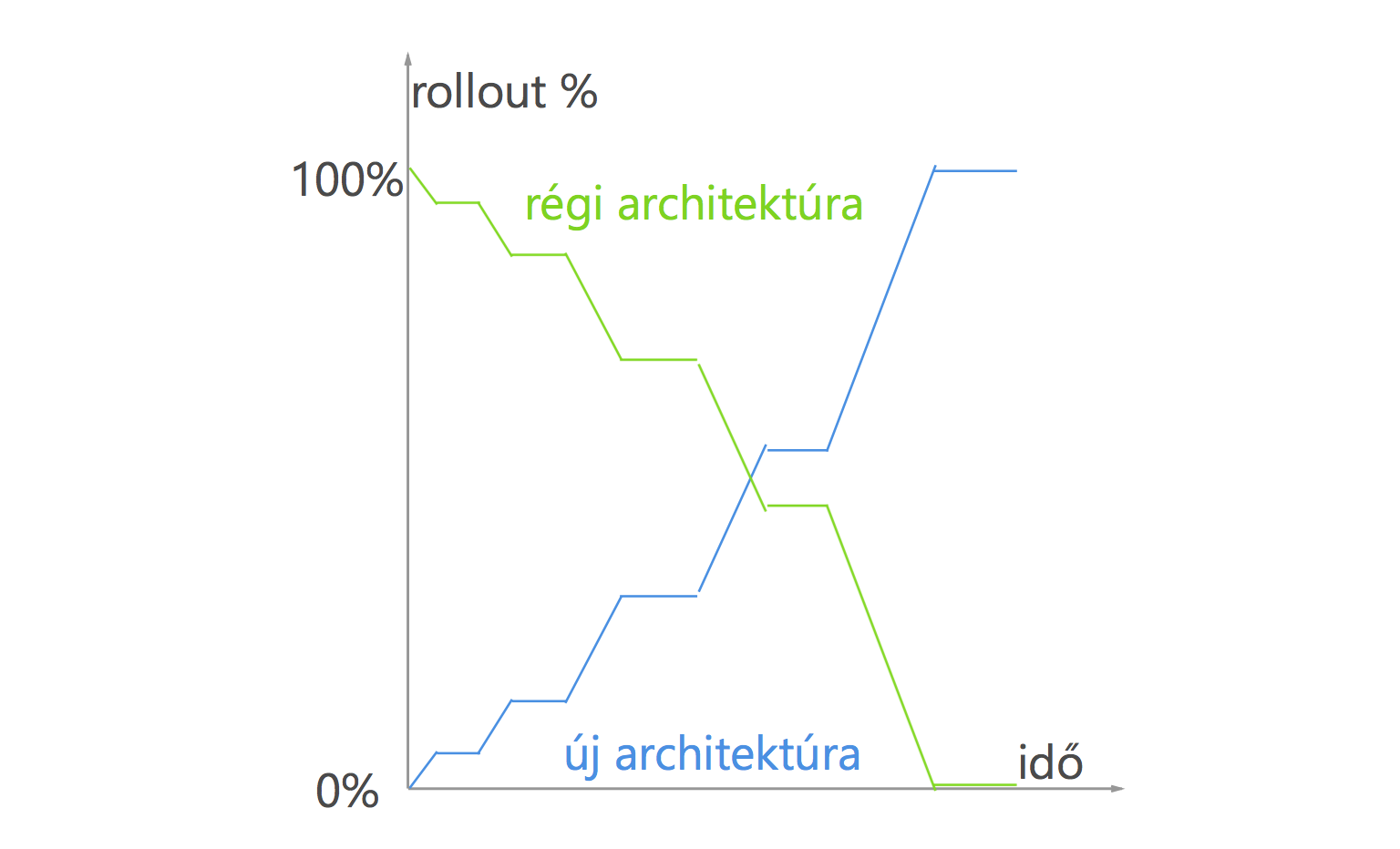
Minden nagyobb változtatást csak szakaszosan érdemes bevezetni. Szaknyelven: staged rollout. Előbb nézzük meg, hogy kicsiben működik-e. Aztán kicsit nagyobban. Aztán még nagyobban. És így tovább, amíg mindenkinél működik. (Hogy ez mennyire best practice, azt kevés dolog mutatja jobban, mint hogy a Facebook így tesztel minden változtatást. Ha legközelebb valami apróság változik a Facebookodon, akkor éppen neked rolloutolnak valami új dolgot.)
Na, nekünk a konkrét tervünk ez volt:
- Spin-upolunk pár Azure szervert 4 különböző régióban és a userek 0.5%-ának rolloutolunk. 3x annyit indítunk, mint amire tervezzük, hogy szükségünk van. A cél, hogy a szerverek 30% alatti CPU és memória kihasználtságon legyenek
- Lemérjük a terhelést, nézzük a logokat 48 óráig
- Duplázzuk a rollout mértékét, ha minden jó. Ha szükséges, előtte megnöveljük a szerverek számát
- Rollback: Ha bármi nem jól alakul, egyből visszaállunk a korábbi állapotra
- Ismételjük mindezt újra, amíg 100%-os az átállás az új rendszerre.
- Optimalizálunk a folyamat végén, a méréseink alapján (pl ha túl sok gép fut, akkor lekapcsolunk párat, illetve dinamikusabb load balancinget fejlesztünk később)
Az átállás pedig valahogy így nézett volna ki. A tervünk az volt, hogy két és fél hét alatt átlállunk az új architektúrára.
Houston, van egy kis gond
Az átállás gond nélkül haladt. 0.5%... 1%... 2%... 5%... 10%. Ekkor körülbelül 900 req/sec-nél tartottunk. És amikor a felhasználók 20%-ának rolloutoultunk, akkor beszakadt minden. A szervereken a requestek timeoutoltak, mi pedig egyből rollbackeltünk, és nekiálltunk vizsgálódni.
Kiderült, hogy a gond 1,000 req/sec körül jelentkezik. De ahogy tovább mértünk, pár nap alatt kiderült, hogy nem az 1,000 req/sec volt a probléma veleje, hanem egyetlen data centerünk sem tudott valamiért 350 req/sec-nél több hívást kiszolgálni: a requestek elkezdtek meghalni. És furcsa módon, nem igazán számított, hogy 5, 10, vagy 20 virtual machine futott a data centerben: mindig ugyanez volt a gond.
Nagyon úgy tűnt, hogy az Azure-al lehet valami limitáció: úgyhogy kapcsolatba léptünk az Azure-os csapattal. Meglepő módon viszont ők sem tudtak segíteni egyből: több hetet kértek, amíg foglalkozni tudnak vele. Így aztán el kellett döntenünk, hogy várunk-e akár egy hónapot, vagy nekiállunk a baj forrását megtalálni mi magunk.
Mivel a Microsofton belüli csapat voltunk, ezért könnyebb dolgunk kellett volna, hogy legyen bármilyen Azure gonddal. Alapból hozzáférésünk volt a prioritásos szupporthoz, amit igénybe is vettünk. Egyből a fejlesztőkkel akartunk beszélni - de ez nem egészen így működött.
A helpline felhívásakor meg kellett mondanunk, hogy mennyire sürgős a gondunk. Mondtuk, hogy nagyon. Aztán el kellett mondanunk a problémát, ami vagy 10 percig tartott - a vonal másik végén nem volt igazán képben az illető, hogy mi is történik. Miután mindez megvolt, 12 óra múlva kaptunk egy emailt egy support ticket-el. Mint kiderült, a vonal másik végén az illető egyszerűen begépelte, amit mondtunk. Mi vakartuk a fejünket, hogy ennek mi értelme volt, de békésen tovább vártunk.
Ezután kb másfél hétig ide-oda ment a ticket, a végén meg le akarták zárni azzal, hogy "nem reprodukálható". Eddigre már eléggé elegünk lett a "prioritásos" supportból, és miután néhányszor elmondtuk, hogy tényleg 400 millió embert tartunk fel ezzel a hibával, sikerült átjutnunk egy fokkal feljebbi csapathoz. Itt mondták, hogy legalább 3 hét kell nekik, mire lesz idejük rendesen reprodukálni a hibát, felépítve egy rendszert, ami hasonló a mienkhez.
Őszintén szólva abban igazuk volt az Azure supportnak, hogy amit nehéz reprodukálni, azt nehéz megjavítani. A mi esetünket pedig csak extra nagy terheléssel lehetett reprodukálni. Ennél a pontnál viszont a 3 hét várakozás helyett a saját kezünkbe vettük a dolgokat.
Vissza a hálózati alapismeretekhez
Pár hét alatt a C#, .NET keretrendszer, Windows, és az Azure szinte minden networkinggel kapcsolatos anyagát átnéztük tüzetesen. A proxy Windows 2012-es OS-en futott, IIS szerveren, ASP.NET MVC keretrendszeren, C# nyelven. Miután a kód és az architektúra minden részét átnéztük, egyértelmű volt, hogy kifutunk a kapcsolatokból. És sok debuggolás és kísérletezés után az is egyértelmű lett, hogy a probléma a TCP rétegben történik, az oprendszer networking rétegében. Ugyanis, amikor reprodukáltuk a hibát, és kiloggoltuk a hálózati állapotot, akkor több száz kapcsolatot láttunk, aminek a státusza TIME_WAIT volt. A TIME_WAIT ugyanakkor egy socket TCP állapotát jelzi: ez adta az első nyomot a kutatáshoz.
Én anno a TCP protokollról az egyetemen, számítógépes hálózatok tárgy keretében tanultam, de ezt a tudást korábban soha nem kellett használnom. Hát, most ideje volt felfrissíteni ezt a tudásomat. Ugyanis TCP alapbeállítása mellett egy szerver maximum 270 req/sec-et tud kiszolgálni - ami kísértetiesen közel volt a 350 req/sec-hez, amit mi mértünk.
Az egész dologban a furcsa viszont az volt, hogy hiába változtattunk a TCP-hez köthető beállításokat, vagy raktunk több, illetve kevesebb gépet a data centerbe, nem mozdult a 350 req/sec-es limit. Ekkor viszont már egészen biztosak voltunk benne, hogy az Azure TCP beállításai okozzák a gondot. Felvettük a kapcsolatot egy Azure-os csapattal, akik megerősítették, hogy deploymentenként maximum 350 req/sec-et fogunk tudni csak elérni.
Egy HTTP kapcsolat nyitásakor a HTTP réteg alatt egy TCP kommunikációs csatorna nyílik meg. Ez a csatorna biztonságos adatátvitelt garantál. Amikor az adatátvitel megtörténik, akkor viszont nem zárul be egyből, hanem nyitva marad TIME_WAIT másodpercig.
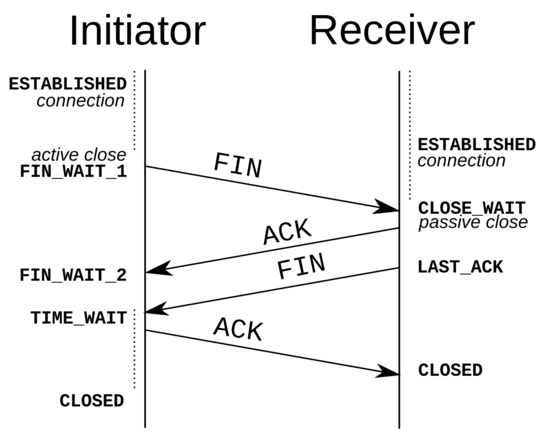
A Windows-os gépeken az alapértelmezett TIME_WAIT érték 4 perc, azaz 240 másodperc. Ha viszont folyamatosan nyitunk új requesteket, akkor másodpercenként hány requestet tudunk kiszolgálni egyszerre? A TCP 65,000 port címet tud használni új kapcsolatokra (socketekre). Ha egy kapcsolat 240 másodpercig van nyitva, akkor átlagosan másodpercenként kb 270 új requestet tudunk nyitni. Ugyanis 65,000 req / 240 sec = 270req/sec). Szóval ha ennél több hívást akarsz kiszolgálni egyetlen gépen, akkor állítsd át ezt a TIME_WAIT értéket valami rövidebbre (és vegyél elég CPU-t és memóriát is a gépbe, persze!)
Az Azure limitációja viszont, úgy tűnt, mint ha egy TIME_WAIT = 180sec értéken futott volna. Elsőre nem értettük, ez hogy lehet, de aztán beugrott. A NAT (Network Address Translation) a kulcsa mindennek.
Amikor az Azure egyik data centerében 10 virtual machine-t indítottunk, ezek nem kaptak külön IP címet. Egy úgynevezett deployment-be voltak összefogva, egy közös IP címmel. Ez a cím pedig NAT-al volt megosztva köztük. Minden kimenő TCP kapcsolatot az Azure kezelt: és a NAT szinten a TCP kapcsolatok TIME_WAIT-ja 180 mp-re volt beégetve: ezt mi nem tudtuk megváltoztatni. Ezt az Azure-on dolgozó mérnökök is végül megerősítették, mint limitáció.
Mehet a buli
Körülbelül 3 hetünkbe telt, amíg megértettük, hogy miért indultak be ezek a hibák, amikor kb 40 millió ember, körülbelül 1,000 req/sec-el érte el a szervereinket. Most, hogy tudtuk, mi a gond, már pofon egyszerű volt skálázni. Egyszerűen a data centereken belül több deploymentet hoztunk létre. Minden deploymentben 4 virtual machine volt, és minden deployment limitje 350 req/sec volt.
Egy extra hét volt, hogy írjunk automatizált scripteket, amik ezeket a deploymenteket felhúzzák, illetve leállítják - ekkor ugyanis ezt még nem lehetett egy kattintással megcsinálni az Azure vezérlőpaneléből.
"70% és stabil 36 órája. 7,000 req/sec-en van a rendszer. Minden data center zöld, az összes deployment 250 req/sec alatt kapja a forgalmat. Mehetünk 85%-ra?"
"Nyomjuk fel 100%-ra."
"Mind a 400 millió embernek? Biztos vagy benne?"
"Már 36 órája semmi vészes nem történt, duplázzuk meg a rolloutot, mert egyébként örökké fog tartani, és a héten végezni akarok. Mehet!"
"Rendben, 85%-on vagyunk."
"100-at mondtam."
"Emlékszem, mi történt, amikor legutóbb hallgattam rád."
5 fontos dolog, amit itt tanultam
Elejétől a végéig körülbelül 2 hónapig tartott a projekt maga. Tanulni viszont többet tanultam, mint máskor 6 hónapa alatt.
1. Amíg nem érted, miért nem működik valami, addig nem ástál elég mélyre
Ha valami nem működik, kezdd el szisztematikusan végigvenni, hogy mi lehet a gond. A számítógépek teljesen logikusan működnek, és mindennek megvan a maga oka. Például mi eleinte végigvettük, hogy mi lehet a gond a kódunkkal. Nem találtunk semmit, és feljebb léptünk az operációs rendszerhez. Itt végigpróbáltuk a lehetséges hibákat, de szintén minden oké volt. És végül így értünk el az Azure "operációs rendszeréhez", az Azure Fabrichoz. És kiderült, hogy tényleg itt volt a gond.
2. Soha nem tudhatod, milyen ismeretmorzsa segíthet ki bizonyos helyzetekben
Egyetem másod- vagy harmadévében tanultunk a TCP hálózatokról. Engem soha nem érdekelt igazán a hálózati programozás. Sok-sok évvel később viszont mégis ez az ismeretmorzsa volt, ami kisegített. Már messze nem emlékeztem, hogy pontosan hogy is működik a TCP - de tudtam, hogy nagyjából mit keresek. A Wikipedia pedig bármikor segít felfrissíteni a régi ismereteket.
3. Mindig, minden körülmények között loggolj
Amikor láttuk, hogy gond van az új verzióval és rollbackeltünk, rengeteg logunk volt. Ezeken pedig végig tudtunk menni egyesével, és egy csomó plusz infót kaptunk belőlük. Például kapásból kizártunk egy csomó lehetőséget, mint program- vagy memóriahiba. A logok az esetek nagy részében nem fontosak, de amikor valami gond van, akkor aranyat érnek.
4. Mindig legyen egy rollout, és egy rollback terved
Ha valami elromolhat rollout közben, az el is fog romlani. Ha nem vagy erre felkészülve, akkor kapkodni fogsz, és csak rosszabb lesz a helyzet. Nekünk volt rollback tervünk - és biztosak voltunk benne, hogy soha nem kell használnunk. Hát, pedig kellett. Én pedig akkora sokkban voltam, hogy gépiesen követtem a rollbacket - szerencsére kellően egyszerű is volt. Egyébként ezt nem csak én mondom: egy hete a Google Cloud leállt 17 percre. A Google közzétette a vizsgálatukat, ahol kiderült, hogy azért csak 17 percre, mert egyből életbe léptették a rollback tervet, mielőtt bármit is megvizsgáltak volna.
5. Több százmillió embernek építeni valamit: nem tehetség, hanem kőkemény tanulás
Nem kell semmilyen különös tehetség ahhoz, hogy egy ekkora terhelésű rendszert építsél. Viszont annál több tudás kell, amit közben felszedsz: mert ezeket tankönyvekben nem tanítják sehol. Én közel nulla skálázási tudással építettem egy 1 millió embert kiszolgáló iWiW app backendet - mindent útközben tanultam meg. István programozási ismeretek nélkül, saját magát tanítva, pár év múlva több száz millió embert kiszolgáló MySQL architektúrát üzemeltetett a Facebooknál. Zsolt pedig úgy épített egy napi 150 millió ajánlást elemző rendszert, hogy semmit nem tudott a recommendation engine-ekről előtte.
Amikor elkezdtük a projektet, nem azon agyaltam, hogy "Te jó ég, mennyien fogják ezt a rendszert használni". Sokkal inkább az volt a fejemben, hogy "Ilyet még sose csináltam - tök jó! Hogyan is kezdjük?". Nyilván sokat segített, hogy egy jó csapat volt körülöttem, akikkel meg tudtuk beszélni a problémákat - ami így sokkal gyorsabban ment sokszor, mintha egyedül csináltam volna. A különbség a végén aközött, hogy tudok-e építeni egy ilyen rendszert vagy nem? Az, hogy útközben csomót tanultam: a szerverek skálázásáról és a cloud-ról, illetve a saját hibáinkból, és azok megoldásából is. Most, hogy egyszer ezt megcsináltam, másodszor már sokkal könnyebben újra meg tudnám ezt csinálni.
Minden jó, ha a vége jó. Amikor végül mind a 400 millió embernek kiment az új architektúra, akkor lélegzetvisszafojtva figyeltük, hogy minden rendben van-e. Minden rendben volt. Annyira, hogy az emberek 99.99% százaléka semmit nem vett észre a változásból. Ez már csak egy ilyen projekt volt. Ettől még a csapattal elmentünk egy jót sörözni és megünnepelni, hogy egy akkora terhelésű proxyt építettünk, amihez közelit se csinált egyikünk se korábban.